 My GeoNetwork catalogue
My GeoNetwork catalogue
Sentinel-2
Provided by
Type of resources
Available actions
Topics
Keywords
Contact for the resource
Update frequencies
Service types
-
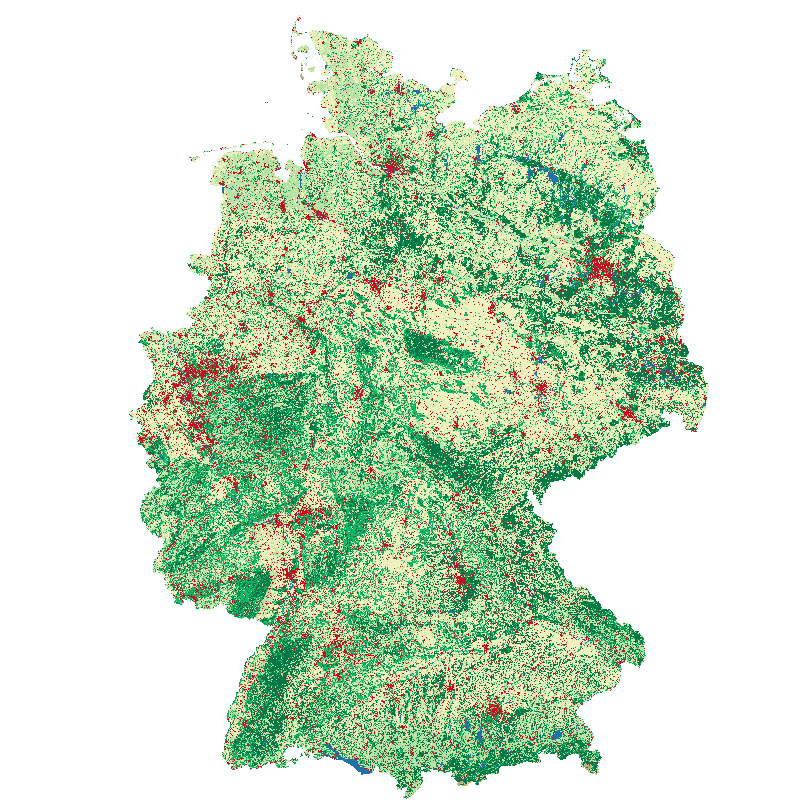
This land cover classification of Germany was created using Sentinel-2 imagery from the years 2015 to 2017 and LUCAS 2015 in-situ reference data (https://ec.europa.eu/eurostat/web/lucas). It contains seven land cover types: (1) artificial land, (2) open soil, (3) high seasonal vegetation, (4) high perennial vegetation, (5) low seasonal vegetation, (6) low perennial vegetation and (7) water with a spatial resolution of 10m x 10m. For further information, please see the following publication: https://doi.org/10.1016/j.jag.2020.102065
-

The Sentinel-2 fractional vegetation cover (fCover) product for the Netherlands was produced as part of the NextGEOSS project at the German Aerospace Center (DLR). The goal is to derive abundance maps from atmospherically corrected Sentinel-2 multispectral images for: photosynthetically active vegetation (PV); and for combined non-photosynthetically active vegetation (NPV) and bare soil (BS). The fCover product for the Netherlands has been generated by processing 10 cloud-free Sentinel-2 tiles which covered the country on 8 September 2016. The map has a spatial resolution of 60m x 60m. The Sentinel-2 scene classification layer was used to ensure that the spectral unmixing was only performed on areas of vegetation or soil. The abundance maps were made by performing MESMA unmixing on each pixel from an endmember library of PV and combined NPV + BS spectra. The purest pixels in a scene, called endmembers, were extracted using the Spatial-Spectral Endmember Extraction (SSEE) approach. The PV and NPV+BS endmembers were classified with a random forest approach and selected to form the spectral library. The spectral library was used in the µMESMA unmixing to get the PV and NPV+BS abundances.
-
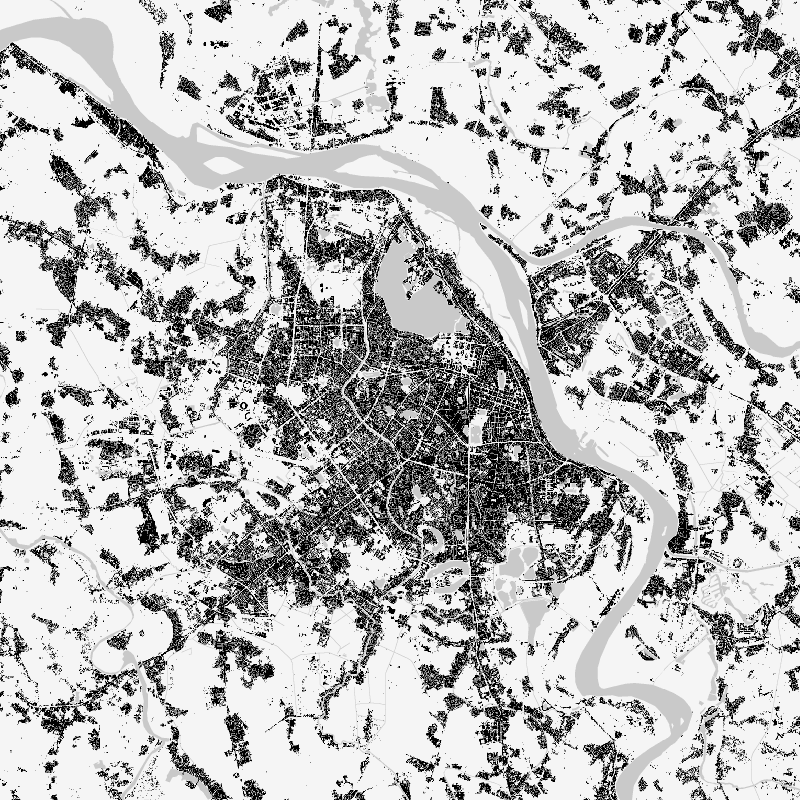
The World Settlement Footprint (WSF) 2019 is a 10m resolution binary mask outlining the extent of human settlements globally derived by means of 2019 multitemporal Sentinel-1 (S1) and Sentinel-2 (S2) imagery. Based on the hypothesis that settlements generally show a more stable behavior with respect to most land-cover classes, temporal statistics are calculated for both S1- and S2-based indices. In particular, a comprehensive analysis has been performed by exploiting a number of reference building outlines to identify the most suitable set of temporal features (ultimately including 6 from S1 and 25 from S2). Training points for the settlement and non-settlement class are then generated by thresholding specific features, which varies depending on the 30 climate types of the well-established Köppen Geiger scheme. Next, binary classification based on Random Forest is applied and, finally, a dedicated post-processing is performed where ancillary datasets are employed to further reduce omission and commission errors. Here, the whole classification process has been entirely carried out within the Google Earth Engine platform. To assess the high accuracy and reliability of the WSF2019, two independent crowd-sourcing-based validation exercises have been carried out with the support of Google and Mapswipe, respectively, where overall 1M reference labels have been collected based photointerpretation of very high-resolution optical imagery.
-

This dataset includes the normalized difference vegetation index (NDVI) derived from Sentinel-2 imagery. Using the Google Earth Engine, all granules with a cloud cover below 60% were used as input. Cloudy pixels (referring to quality layer QA60) were masked as well. Eventually, a median mosaic was composed over the whole observation period. It was also used as input for a land cover classification (see: Land Cover DE - Sentinel-2 - Germany, 2015).
-

This vector dataset is based on a 10 m resolution raster dataset that shows forest canopy cover loss (FCCL) in Germany at a monthly resolution from September 2017 to September 2024. Results at pixel level were aggregated at municipality, district, and federal state level. For the results at administrative level we differentiate between deciduous and coniferous forests. We use the stocked area map 2018 (Langner et al. 2022, https://doi.org/10.3220/DATA20221205151218 ) as a reference forest mask. We differentiate between deciduous and coniferous forests by intersecting the stocked area map with a tree species map (Blickensdoerfer et al. 2024). Pixels of the classes birch, beech, oak, alder, deciduous trees with long lifespan and deciduous trees with short lifespan were classified as deciduous forest and pixels of the classes Douglas fir, spruce, pine, larch and fir as coniferous forest. The coverage of the two datasets is not identical, which is why a few areas of the forest reference map remained unclassified. These were filled with the dominant leaf type map of the Copernicus Land Monitoring Service (CLMS 2025). Therefore, the vector data at administrative level contains information about unclassified forest areas and the total forest area as the sum of deciduous, coniferous, and unclassified forests. The FCCL confidence at pixel level is lowest at the end of the time series because the number of repeated threshold exceedance is used as a criterion to record forest canopy cover losses. Therefore, we excluded July 2024 through September 2024 from the annual and overall statistics and summarized the respective FCCL as additional attribute. The dataset is a fully reprocessed continuation of the assessment in Thonfeld et al. (2022).
-

This raster dataset shows forest canopy cover loss (FCCL) in Germany at a monthly resolution from September 2017 to October 2025. It is similar to the product developed by Thonfeld et al. (2022) but was fully reprocessed and updated to reveal the most recent forest disturbance dynamics (Thonfeld et al. 2026). The combination of Sentinel-2A/B and Landsat-8/9 data allows for a high temporal resolution while the pixel size of the product is 10 m. The results are clipped to the stocked area 2018 mapped by the Thünen-Institute (Langner et al. 2022, https://doi.org/10.3220/DATA20221205151218). The dataset contains predominantly larger canopy openings resulting from different drivers but also larger clusters of standing deadwood. FCCL can result from abiotic (e.g. wind, fire, drought, hail) drivers, biotic (e.g. insects, funghi) drivers or a combination of both as well as from sanitary and salvage logging and planned harvest. The first version with canopy cover losses from January 2018 - April 2021 (Thonfeld et al. 2022) can be accessed here: https://geoservice.dlr.de/web/datasets/tccl.
-

The World Settlement Footprint (WSF) 3D provides detailed quantification of the average height, total volume, total area and the fraction of buildings at 90 m resolution at a global scale. It is generated using a modified version of the World Settlement Footprint human settlements mask derived from Sentinel-1 and Sentinel-2 satellite imagery in combination with digital elevation data and radar imagery collected by the TanDEM-X mission. The framework includes three basic workflows: i) the estimation of the mean building height based on an analysis of height differences along potential building edges, ii) the determination of building fraction and total building area within each 90 m cell, and iii) the combination of the height information and building area in order to determine the average height and total built-up volume at 90 m gridding. In addition, global height information on skyscrapers and high-rise buildings provided by the Emporis database is integrated into the processing framework, to improve the WSF 3D Building Height and subsequently the Building Volume Layer. A comprehensive validation campaign has been performed to assess the accuracy of the dataset quantitatively by using VHR 3D building models from 19 globally distributed regions (~86,000 km2) as reference data. The WSF 3D standard layers are provided in the format of Lempel-Ziv-Welch (LZW)-compressed GeoTiff files, with each file - or image tile - covering an area of 1 x 1 ° geographical lat/lon at a geometric resolution of 2.8 arcsec (~ 90 m at the equator). Following the system established by the TDX-DEM mission, the latitude resolution is decreased in multiple steps when moving towards the poles to compensate for the reduced circumference of the Earth.
-

The product shows tree canopy cover loss in Germany between January 2018 and April 2021 at monthly temporal and 10 m spatial resolution. The basic principle behind this map is to compute monthly composites of the disturbance index (DI, Healey et al. 2005), a spectral index sensitive to forest disturbance, from all available Sentinel-2 and Landsat-8 data with less than 80 % cloud cover. These monthly composites are then compared to a median composite of the DI for 2017, which serves as a reference. After applying a threshold to the difference image, the time series of detected losses is checked for consistency. Only losses recorded continuously in all observations of a pixel until the end of the time series are considered. The dataset does not differentiate between the drivers of the losses. It depicts areas of natural disturbances (windthrow, fire, droughts, insect infestation) as well as sanitation and salvage logging, and regular forest harvest. The full description of the method and results can be found in Thonfeld et al. (2022).
-

Grassland mowing dynamics (i.e. the timing and frequency of mowing events) have a strong impact on grassland functions and yields. As grasslands in Germany are managed on small-scale units and grass grows back quickly, satellite information with high spatial and temporal resolution is necessary to capture grassland mowing dynamics. Based on Sentinel-2 data time series, mowing events are detected throughout Germany and annual maps of the grassland mowing frequency generated. The grassland mowing detection approach operates per pixel, including preprocessing of the Enhanced Vegetation Index (EVI) time series and a calibrated rule-based grassland mowing detection which is specified in more detail in Reinermann et al. 2022, 2023.
-
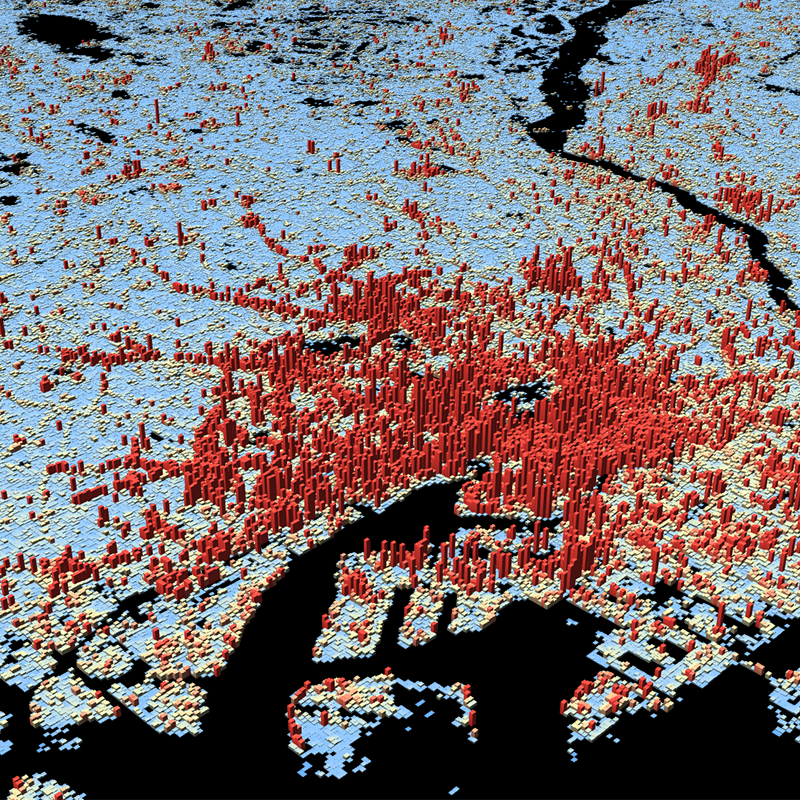
This dataset is a derivative of the WSF3D raster dataset tailored for the web. As a tiled vector dataset, it enables dynamic client-side visualization of the WSF3D metrics